在人工智能的宏伟画卷上,大模型如图璀璨的星辰,不仅照亮了技术的未来,也为行业的变革描绘出了更多的可能性。对诸多企业而言,大模型在推理、训练等方面的能力有望为自身带来更加深层次的价值和服务,满足AI时代下的多元化需求,在数智转型的道路上加速前行。
在上周举办的火山引擎2024 FORCE原动力大会上,火山引擎为业界带来了一系列全新产品及升级,并携手英特尔共同发布了搭载英特尔至强6性能核处理器的第四代通用计算型实例g4il,以更加卓越的计算性能和效率,为传统企业级应用、AI应用和未来更复杂的应用构建坚实可靠的算力基石。
AI上云激发数字原动力,g4il云实例加速业务增长
近年来,以生成式AI为代表的人工智能和大模型训练的新型应用在全球范围内都大量拉动了对算力的巨大需求,也突显了智算平台基础设施的重要性。特别是在如今的大模型时代,无论是训练和托管大模型都会产生大量的成本开销,对那些希望通过AI实现业务持续增长以获得新机遇的企业来说,上云无疑是解决这个问题的最优解。
火山引擎弹性计算产品负责人王睿表示,通过海量内外资源共池,火山引擎可以满足企业在托管AI技术、技术智算化转型过程中的算力需求。通过共池,一方面可以把超大规模的资源复用带来的议价能力、成本红利释放给火山引擎的终端用户。另一方面,通过超大规模集团内外共池带来的议价能力,可以把成本红利返还给客户。通过资源池的整合和灵活调配,火山引擎目前已经实现了百万规模的资源弹性,天级别可提供50万核的弹性能力,单日峰值可以达到100万核,弹性效率可在分钟级别实现10万核的扩展。
而基于至强6处理器和火山引擎自研DPU的新一代云实例g4il则能进一步激发企业客户的数字原动力,助力它们实现业务增长,与上一代相比,第四代实例在整机的计算、存储、网络性能等方面都得到了大幅度提升。其中,网络和存储性能提升了100%,IOPS和PPS性能提升30%以上,此外,在客户常用的数据库、Web应用和视频编解码场景中,g4il也有20%以上的提升。
此外,通过创新的双单路服务器架构,g4il还降低了整体的爆炸半径,有力保障了产品稳定性,并进一步丰富了功能,如新增大包传输能力、机密计算能力,以及支撑最新云盘吞吐类型SSD。
同时,由于至强6处理器新增了对MRDIMM高速内存和AMX FP16指令集的支持,也为AI推理加速提供了更优的底层基础环境。火山引擎基于开源模型Llama27B上实现了大幅性能提升,与基于第五代至强和通用DDR5内存的实例相比,基于第六代至强和MRDIMM内存的实例吞吐性能最高实现了80%的提升,同时相比单卡的A10和L20 GPU实例也有显著的性能优势。
安全性方面,针对云上的AI场景,火山引擎则携手英特尔打造了端到端的安全解决方案,并针对固件、内核、虚拟化和操作系统等方面进行了深度调优,因此,即便在机密计算云服务器上开启内存加密等功能,也可以将性能损失降到最低。
为专用负载而生,至强6内置加速器提升算力体验
现如今,随着细分场景的增多,行业应用也越来越复杂,单纯依靠核心频率的提升和核心数量的增强,实际上并不能很好地满足真实工作负载场景下对CPU性能的高要求,英特尔也深知这一点,凭借长期而广泛的用户需求收集,英特尔专门针对人工智能、5G网络、数据分析、科学计算等现代工作负载引入了全新的设计理念,并采用系统级的设计方法,在CPU芯片架构中内置了专用工作负载加速器,以提高性能和效率。
除了加速深度学习实时推理和训练性能提升的英特尔AMX加速器之外,至强6处理器上还内置了不少针对专用负载的加速器,例如IAA、DSA和QAT。
其中,英特尔存内分析加速器IAA主要用于加速内存计算,可以有效提高内存查询吞吐量,减少内存数据库和大数据分析工作负载的内存占用;英特尔数据流加速器DSA主要用于解决数据中心中内存搬移的问题,可以加快CPU、内存、缓存以及存储和网络设备之间的数据移动。
而英特尔数据保护与压缩加速器QAT则提供了加速网络吞吐量以及压缩解压缩的功能,从架构角度考虑,由于其内置在CPU之中,因此不需要额外的PCIe卡,除了节省成本之外,也能带来以下三方面的好处:
第一是高性能,Gzip的压缩每个核大概每秒只能达到100MB的速度,而QAT可以达到5GB/s。
第二是可扩展性,目前至强6处理器上的QAT最多可以支持4个,可以针对实际需求进行定制化。
最后则是绿色计算。QAT虽然拥有很高的性能,但功耗却非常低,在存储等场景中,可以通过QAT加速器来节省CPU开支,以提升TCO。

据介绍,英特尔QAT主要可以提供三方面的能力,首先是非对称加解密,主要用于Web服务、负载均衡器、内容分发网络中的一些TLS握手的过程;其次是对称加解密,基于至强6处理器内置的AVX-512指令集,可以有效节省CPU消耗;最后则是压缩和解压缩,QAT支持非常丰富的压缩和解压缩能力,如LZ4、Gzip、ZSDT等等。
性能方面,以LibZstd压缩库为例,QAT可以支持LibZstd的压缩功能,与ZSTD社区版1.5.5-L5相比,使用QATL9压缩时,即使CPU仅使用14个核心加上1个QAT的带宽,也能实现与52个CPU核心相当的3.4GB/s压缩速度。这意味着使用QAT可以大幅减少所需的核心数,同时保持相似的压缩率,并且带来70W的功耗节省,从而显著提升性能功耗比。
Data for AI,英特尔助力企业AI转型
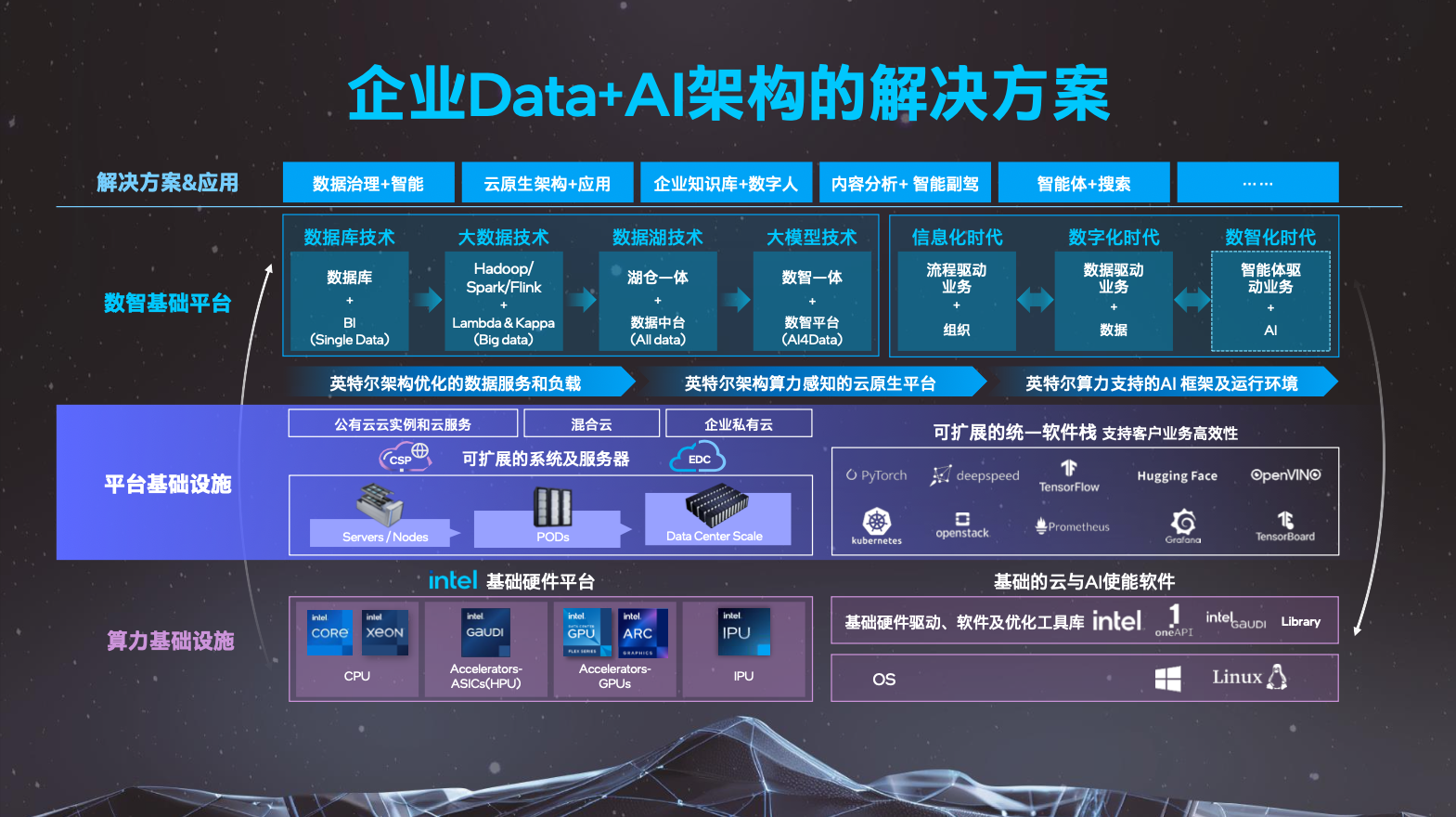
随着人工智能应用成熟和大模型的加速落地,企业拥抱AI已经是大势所趋,根据英特尔的观察,企业数智基础平台的演进过程主要可以从两个维度来看。
从技术维度看,企业数智技术经历了数据库、大数据、数据湖以及大模型爆发几个阶段,目前大数据技术还处在发展和探索期,而湖仓一体的架构则相对成熟,并且已经产生了大量应用,而这些应用正好可以用来向上扩展支持大数据应用,这也是“Data for AI”要实现的目标。
从业务维度来看,企业已经经历了流程驱动业务和数据驱动业务两个阶段。其中流程驱动业务包括业内耳熟能详的CRM、ERP系统,数据驱动业务则涉及到数据中台、数据平台等等。目前的发展趋势是智能体驱动业务,不过也处于发展和探索期,还没有在很多企业里得到实践。
针对算力基础平台,英特尔可以凭借广泛的产品基础提供底层硬件,例如CPU、GPU、Gaudi加速器等等,从而为平台基础设施提供支撑,包括各大公有云的云服务以及私有云的企业业务。
围绕企业Data+AI的架构和发展趋势,英特尔也做了三方面的工作:
第一,提供了英特尔架构优化的数据服务和负载。
第二,提供了英特尔架构算力感知的云原生平台。
第三,提供了基于英特尔算力支持的AI框架和运行环境。
针对包括大模型在内的整个AI领域,英特尔也能提供完整的云边端一体AI推理解决方案,基于英特尔至强CPU、Gaudi加速器、锐炫显卡、边端至强工作站系列产品以及酷睿桌面系列产品等异构算力平台,在应用算力之上提供一个跨云边端的完整软件技术栈。这其中还有国内非常流行的vLLM大模型服务推理框架。此外英特尔也提供了基于算力感知的云原生平台,可以把底层的各种异构算力纳入到云原生平台中,形成各种异构资源池,从而灵活地为上层的大模型应用提供服务。
“近两年,以生成式AI为代表的人工智能技术迎来了一轮全新的发展浪潮,而在技术的演进下,AI的边界也在不断被拓展,一个超乎想象的未来正以惊人的速度向我们走来。在此过程中,我们见证了基础通用大模型能力的不断刷新,也在持续通过技术创新降低算力成本、功耗、技术门槛,以加速行业落地。基于此,英特尔将持续与火山引擎携手打造高性能异构算力,提供云与AI深度融合的服务能力,助力AI应用赋能产业变革。”英特尔市场营销集团副总裁、中国区云与行业解决方案和数据中心销售部总经理梁雅莉在最后表示。

本文属于原创文章,如若转载,请注明来源:打造AI时代弹性算力底座 英特尔至强6助力火山引擎g4il释放数据价值https://server.zol.com.cn/932/9320951.html