产业数字化的深入使得智能场景日趋复杂,所需的IT架构也随之变得多元化。在传统的通用计算之外,XPU架构如雨后春笋般涌现出来,以GPU、IPU、NPU为代表的专用计算正在AI/ML等领域大放异彩。而作为首个专为机器智能设计的处理器,IPU在与其他用于AI计算硬件的角逐过程中,已经显示出差异化的优势。前不久,Graphcore公布了其参与MLPerf测试的结果,其在ResNet-50和BERT模型中的训练性能均取得了高光表现。“我们一直在强调IPU是一个创新的平台,可以帮助创新者达成此前无法做到的任务。如今,我们已经能够证明,Graphcore IPU在一些主流应用上的表现要优于GPU。无论传统应用还是前沿应用,Graphcore都可以让新技术和新架构快速落地,为客户带来可观的商业回报。”Graphcore大中华区总裁兼全球首席营收官卢涛说。
Graphcore提交的系统,首次加入系统集群
在MLPerf 1.1测试中,Graphcore提交了ResNet-50和BERT两个模型,其中在ResNet-50提交了Closed Division(封闭分区),主要进行图像分类任务,在BERT提交了Closed Division和Open Division(开放分区),主要是在Wikipedia的数据中进行语义理解、智能问答、语义推测等任务。与首次提交的MLPerf训练结果相比,对于ResNet-50模型,Graphcore通过软件优化,在IPU-POD16上实现了24%的性能提升,在IPU-POD64上实现了41%的性能提升;对于自然语言处理(NLP)模型BERT来说,在IPU-POD16上实现了5%的性能提升,在IPU-POD64上实现了12%的性能提升。

Graphcore大中华区总裁兼全球首席营收官卢涛
MLPerf的封闭分区严格要求提交者使用完全相同的模型实施和优化器方法,其中包括定义超参数状态和训练时期。开放分区旨在通过在模型实施中提供更大的灵活性来促进创新,同时确保达到与封闭分区完全相同的模型准确性和质量。通过在开放分区展示BERT训练的结果,Graphcore能够让客户了解产品在实际运行中的性能,从而让他们更倾向于使用此类优化。

MLPerf提交的模型针对横向扩展进行了优化
在ResNet-50模型上,IPU-POD16、IPU-POD64、IPU-POD128、IPU-POD256的训练时间依次为28.33分钟、8.50分钟、5.67分钟、3.79分钟。在BERT-Large模型上,IPU-POD16、IPU-POD64、IPU-POD128的训练时间依次为32.70分钟(Closed Division)/26.05分钟(Open Division,IPU优化)、10.56分钟(Closed Division)/8.25分钟(Open Division,IPU优化)、6.86分钟(Closed Division)/5.88分钟(Open Division,IPU优化)。可以看到,集群规模的增加会让训练时间大幅缩短、显著提高算法工程师迭代模型的效率,并且在Open Division中通过对训练策略、优化器超参、损失函数等的优化,又将训练效果提升了20%。
时隔六个月之后,Graphcore在MLPerf 1.1中的表现有了大幅增长,例如在ResNet-50模型中的IPU-POD16上有24%的提升、IPU-POD64有上41%的提升,在BERT模型中的IPU-POD16上有5%的提升、IPU-POD64上有12%的提升。这些成绩的进步主要归功于软件优化,包括在框架、系统、编译器、核心函数等方面的努力。

IPU-POD16和DGX A100的对比
如果横向对比其他产品,IPU-POD16在ResNet-50模型中的性能表现超过DGX A100,端到端训练时间用时28.3分钟,DGX A100的时间是接近一分钟。值得一提的是,NVIDIA GPU在MLPerf的模型训练中已经是第五次提交,而Graphcore只是第二次提交就取得了不错的成绩。在本轮MLPerf 1.1训练中,Graphcore还为BERT提供了最快的单服务器训练时间结果,为10.6分钟。
Graphcore中国工程总负责人、AI算法科学家金琛介绍称,通过将ResNet-50的epoch(时期)由44减少到38,获得了12%-13%的速度提升,“为什么我们用更少的epoch能够达到收敛?是因为我们使用了分布式的BN(Batch Normalization,批规划)技术,可以减少训练迭代的次数。此外,我们在IPU-M2000上提交后,上面会有4个Replica(多个实例),相当于在一个IPU上放一个模型,这样64个IPU上就有64个模型,为此,我们做了很多工作去优化主机到设备的通信,使得在多个Replica的情况下,分布式训练的性能可以显著提升。原来,可能是受到通信的影响,使得像64个Replica中有一个Replica跑得比较慢,导致训练时间变长,而我们的优化让每个Replica的运行时间大致是一样的。由此,我们让训练效果大幅提升,这也是在IPU-POD64上比在IPU-POD16上提升得更高的原因之一。”

Graphcore中国工程总负责人、AI算法科学家金琛
Graphcore大规模集群的优异表现离不开软件的可扩展性,更大型的POD系统需要软件支持,优化的机器学习框架扩展可以作为Poplar SDK的一部分来提供,可用于支持多个主机服务器以进行应用程序扩展的简单作用启动工具。Graphcore通信库在多IPU之间互联时对模型参数、优化器状态的同步和更新进行了优化,让数据并行时的深度学习能力有所提升,其可作为Poplar SDK版本的一部分提供的优化集合,能够集成到所有支持机器学习框架的IPU中,将应用程序从1个IPU扩展到256个。在设计过程中,Graphcore对多种情况进行了优化,例如模型、数据、内核的变形,以及用系统级软件优化主机到设备的通信、解决数据并行的问题等等,使得用户只需写一个脚本,配置数据实例数量后就能快速实现横向扩展。无论是ResNet-50、BERT,还是GPT2、EfficientNet、ViT,Graphcore对于成熟模型和新模型的适用性都有着很好的表现。
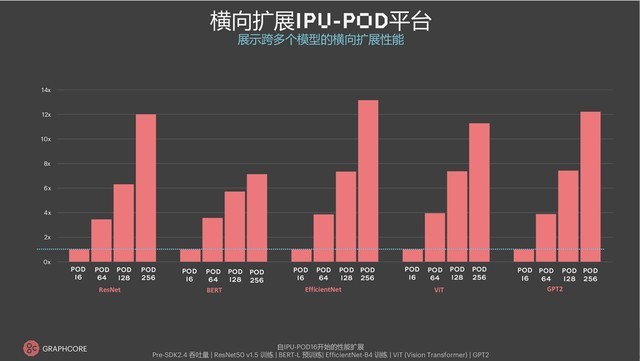
横向扩展IPU-POD平台
自谷歌在2017年推出NLP经典模型BERT起,Transformer就踏上了快速发展的道路,在机器翻译、计算机视觉等多个场景的表现均优于RNN和CNN,通常只需要编/解码器就能达到较好的效果,并且可以高效并行化。因此,Graphcore在选择GPT2、ViT、EfficientNet等新模型进行演示时,就能体现出较好的鲁棒性和可扩展性。以EfficientNet-B4为例,DGX A100端到端的EfficientNet训练时间是70.5小时,IPU-POD16的时间是20.7小时,IPU-POD256的训练时间更是在2小时以内。
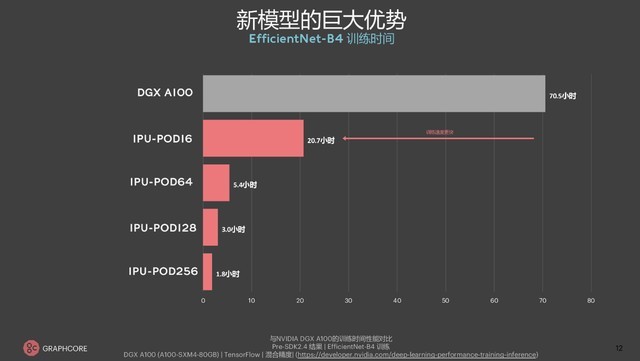
IPU-POD和DGX A100的EfficientNet-B4训练表现对比
为了提升用户的配置灵活性,Graphcore在设计IPU系统时为IPU-M2000的1U机器和x86服务器做了解耦的方案,方便用户调整服务器、处理器数量和AI计算之间的比例。例如,Supermicro、英特尔、谷歌等厂商在CPU和AI加速器之间的配置是1:2,意味着组建AI计算机集群时需要搭配更多的CPU,而Graphcore在类似BERT等场景应用时可以做到1:32,即1个CPU搭配32个IPU,更好的帮助用户降本增效。如果在MLPerf 1.1测试中以CPU为对比维度,那么在单一x86服务器(两颗AMD EPYC 7742)的训练时间上,Graphcore对BERT模型的训练能够低至10.6分钟(Closed Division)、8.3分钟(Open Division),相比之下,DGX A100是20分钟,英特尔提交的Gaudi平台(Intel Xeon Platinum 8280)是80.5分钟。
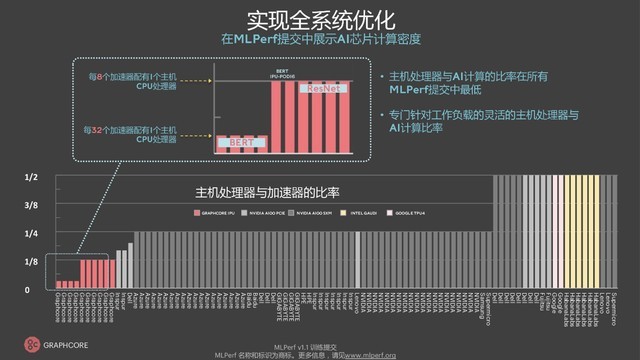
Graphcore的系统级优化
与其他产品不同,IPU仅使用主机服务器进行数据移动,不需要主机服务器在运行时分派代码。因此,IPU系统需要的主机服务器更少,从而实现了更灵活、更高效的横向扩展系统。对于像BERT-Large这样的自然语言处理模型,IPU-POD64只需要一个双CPU的主机服务器。ResNet-50则需要更多的主机处理器来支持图像预处理,Graphcore为每个IPU-POD64指定了四个双核服务器,1比8的比例仍然低于其他的MLPerf测试参与者。
为了根据NLP、CV等不同应用类型的特性进行动态比例调整,Graphcore下了不少功夫,包括优化了IPU代码的执行机制,为CPU减负,将其视为调度器或任务分发器,由IPU承担更多的执行工作。同时,IPU-M2000和服务器之间会通过IPU over Fabric(IPUoF)总线连接,由以太网将IPU连接到x86、arm等平台的服务器,并且IPU无需在主机服务器运行分配代码。
IPU-M2000与x86服务器之间由100G以太网的标准通讯接口连接,支持RoCE/RDMA,可以在不通过CPU的情况下,直接发起数据的访问、访存等操作,进一步提高速率。IPU与服务器的通讯协议被称为IPU-Fabric,可以通过“设备映射/设备ID”的方法将其分装实现类似PCIe的作用,在服务器上复用各种类型的软件。
目前,Graphcore已经先后完成对TensorFlow、PyTorch、Keras、阿里巴巴HALO、PyTorch Lightning、百度飞桨等框架和库的支持,以及对Optimum Library等Hugging Face社区Transformer的支持,Docker和VMware生态也在支持IPU架构。过去半年,Graphcore在生态合作方面进展显著——在金融领域,牛津-英仕曼利用IPU实现了更快的股票预测并提高了准确率;在保险领域,Tractable使用IPU帮助客户进行AI定损;在科学领域,Graphcore帮助欧洲、中国的科研机构和企业准确预测天气情况,实现精准灌溉、防灾减灾;在电信领域,Korea Telecom发布了基于IPU的IPU云;在科学计算领域,Graphcore与ATOS确定了战略合作关系。
自2020年12月首个IPU-POD硬件量产以来,Graphcore的快速发展显而易见。从去年第四季度的IPU-POD16到现在的IPU-POD256,通过硬件集群的增加和软件方面的优化,在ResNet性能上有了50倍的长足提升。如今,Graphcore还在推进强化学习的相关工作,团队规模达到80人左右,通过深度学习、高性能计算等方式在天气预测、分子动力学等领域推动社会的进步。这一系列成绩使得IPU架构受到客户的广泛认可,市场在该领域的投入也逐渐增长。

Graphcore IPU的快速发展
从技术趋势来看,卢涛认为有三个方向。第一是“Transformer-based everything”,Transformer在NLP、CV,以及对话、语音等领域进展迅速;第二,从单一任务到多模态,应用规模越来越大;第三,AI与传统科学场景的融合愈发紧密,天气热测、宇宙学研究等等。这些重要的技术方向也将是Graphcore未来会重点投入的领域。“不管是从指令集还是架构上来看,IPU已经具有广泛的适用性,可以用于CNN、LSTM、Transformer等类型的AI任务,可以便于开发者进行灵活编程。”卢涛表示,“上面提到的技术趋势会指导IPU芯片的发展方向,Graphcore一方面会维持稳健的芯片迭代周期,在同等的体积、功耗、面积上,进一步强化算力和存储能力,另一方面也会加强通信能力,这对构建大规模AI系统来说至关重要。”



本文属于原创文章,如若转载,请注明来源:MLPerf性能测试创新高 Graphcore IPU成为AI计算新选择https://server.zol.com.cn/784/7840994.html