“我们正在经历的一切,远远偏离了地球的正常状态。我们遭遇了各种极端天气——历史性干旱、前所未有的炎热、狂暴的飓风、猛烈的暴风雨、以及灾难性的洪水等等。气候灾害已成为一种‘新常态’。”在SC21期间,NVIDIA创始人兼CEO黄仁勋对人类社会面临的共同危机做出了清晰判断,“我们需要立刻采取行动以应对气候变化。然而,我们所作的努力可能在几十年内都很难感受到其产生的影响。我们很难因为未来的事情去动员大家。但是,当下的我们必须通过亲眼所见和亲身感受来知晓未来,并尽快采取行动。”
NVIDIA利用Earth-2解决气候难题
1850至1900年这一时期以来,人类活动所排放的温室气体导致全球平均温度升高了约1.1°C。过去7年,有可能成为有气象记录以来最热的7年。摆在人类面前的全球气候变暖问题已刻不容缓,但要想加快应对速度,仍需进一步加深认知。如何让现在的人们身临其境的感受到未来的变化?NVIDIA给的答案是模拟,并为此宣布将打造全球最强大的人工智能超级计算机“Earth-2(E-2)”,借助Omniverse平台创造一个地球的数字孪生。
近年来,HPC与AI的融合已是大势所趋,人工智能在高性能计算中的应用能帮助研究人员加快模拟速度,同时保持传统模拟方法的准确性。可以看到,越来越多的超算系统在行业场景中落地开花,基于云的HPC也开始崭露头角。在SC21发布的TOP500榜单上,NVIDIA为355套超算系统提供了加速,占榜单的70%以上,新增系统中90%以上采用了NVIDIA的技术。值得一提的是,来自微软的GPU加速Azure超级计算机在榜单上排名第十,这是基于云的系统首次跻身TOP10。
应对气候变化威胁的“特效药”
据了解,Earth-2由NVIDIA独立出资打造,并会采用新的架构设计以达到高效节能的目的,黄仁勋称其会是“史上最节能的”HPC。考虑到NVIDIA当前拥有的Selene、Cambridge-1等性能强劲的超算系统,Earth-2的表现同样值得期待,甚至会成为“另一个地球的引擎”。根据黄仁勋的说法,要想获得能够模拟全球从海洋、海冰、陆地表面和地下水到大气和云层的整个水循环过程的高分辨率,需要高出当前数百万到数十亿倍的算力。如果按照算力每5年提升10倍的常规标准计算,实现这一目标需要数十年的时间。
通过结合GPU加速计算、深度学习和内嵌物理信息的神经网络的突破,以及AI超级计算机,再加上大量可供学习的观测和模型数据,实现百万倍的加速已成现实,由此带来了超分辨率技术,让10亿倍量级的气候建模精确化变为可能。为此,NVIDIA在计算科学领域投入了大量资源以推动气候环境向好发展。“我们迄今为止发明的所有技术都将用于实现Earth-2。”黄仁勋信心满满地说。
NVIDIA在气候环境领域的努力不止于此。前不久,Atos和NVIDIA宣布成立卓越人工智能实验室(Excellence AI Lab,EXAIL),首批研究项目集中在高性能计算和人工智能的进步所推动的五大关键领域:气候研究、医疗和基因组学、与量子计算的结合、边缘人工智能/计算机视觉以及网络安全。Atos将利用NVIDIA基于Arm架构的Grace CPU、NVIDIA下一代GPU、Atos BXI E级互联技术和NVIDIA Quantum-2 InfiniBand网络平台,开发一台E级计算级别的BullSequana X超算。
为了更准确地预测气候变化,Atos和NVIDIA的研究人员会在欧洲最快的超级计算机Jülich上,运行新的AI和深度学习模型。这种巨型模型可用于预测极端天气事件的演变、及其随全球变暖而发生的变化。JUWELS Booster系统基于Atos的BullSequana XH2000平台,拥有近2.5 exaflops的AI性能,搭载了3744个NVIDIA A100 Tensor Core GPU,采用NVIDIA Quantum InfiniBand网络,有助于更深入地了解气候变化,并对飓风、极端降水、炎热和寒潮等事件进行更准确的长期预测。到2025年,Atos会将自身全球范围的碳排放量减少50%,并在2028年抵消自身所有的剩余排放量。
除此之外,Atos与NVIDIA的合作还涉及更多领域。Atos生命科学卓越中心与40家领先机构合作,利用高性能计算、量子计算和AI来推进医学成像、基因组学和制药领域的发展。EXAIL将利用Atos的计算解决方案和NVIDIA Clara,帮助医疗研究人员和供应商利用嵌入式、边缘、数据中心和云平台,加速药物研发并设计先进的诊断方案。同时,EXAIL还会使用Atos在NVIDIA BlueField DPU上运行的BullSequana Edge,以及NVIDIA Morpheus开放式AI框架,推动计算机视觉、5G和零信任网络安全平台的建设。在Atos的全球六个专门研究计算机视觉的实验室,都将配备最新的NVIDIA Fleet Command技术,用于在分布式边缘基础设施上安全地部署和管理AI应用。
HPC与AI深度融合加速
雨后春笋般的行业场景标志着HPC与AI的融合走向了更深一层,越来越多的科研人员利用AI加快研究的速度,例如今年戈登·贝尔奖(Gordon Bell prize)决赛的四组晋级团队。与此同时,各大企业在争相建造具备E级算力的AI超算。近年来,研究高性能计算和机器学习的论文数量激增,从2018年的约600篇增长到2020年的近5000篇,近期分子动力学、天文学和气候模拟的科学突破也都使用HPC+AI。与此同时,包括HPL-AI和MLPerf HPC在内的新基准也强调了HPC与AI工作负载的持续融合。
HPL-AI使用了混合精度计算,并提供了双精度计算的高度准确性。MLPerf HPC 1.0则在HPC 的三个典型工作负载中测试了AI模型训练,即天体物理学(Cosmoflow,判断望远镜图像中物体的细节)、天气(Deepcam,测试对气候数据中飓风和大气河流的检测)、分子动力学(Opencatalyst,跟踪系统预测分子中原子间力的成效)。每个测试分为两个部分。衡量系统训练模型的速度的指标被称为强标度。其对应的弱标度是衡量系统最大吞吐量的指标,即系统在给定时间内可以训练多少模型。与去年MLPerf 0.7的强标度最佳成绩相比,NVIDIA为Cosmoflow性能提升了5倍,为deepcam性能提高了近7倍以上。
劳伦斯伯克利国家实验室 (Lawrence Berkeley National Laboratory) 的Perlmutter系统使用了5120个NVIDIA A100 Tensor Core GPU中的2048个,在opencatalyst基准中效果显著。在弱标度类别中,NVIDIA使用每个作业16个节点和256个同时作业来主导deepcam。NVIDIA所有的测试都在NVIDIA Selene(如下图),即NVIDIA内部系统和大型工业超级计算机上运行。结果显示,NVIDIA AI平台及其性能再度领先,这是NVIDIA第八次在MLPerf基准中获得最高分,该基准涵盖数据中心、云和网络边缘的AI训练和推理。在本轮测试的8名参与方中,有七名使用 NVIDIA GPU 提交了结果,包括德国于利希超级计算中心、瑞士国家超算中心、美国阿贡国家实验室、劳伦斯伯克利国家实验室、国家超级计算机应用中心和德克萨斯高级计算中心。
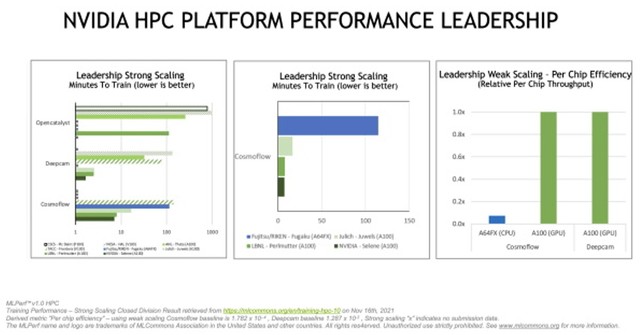
在NVIDIA Selene平台的测试数据
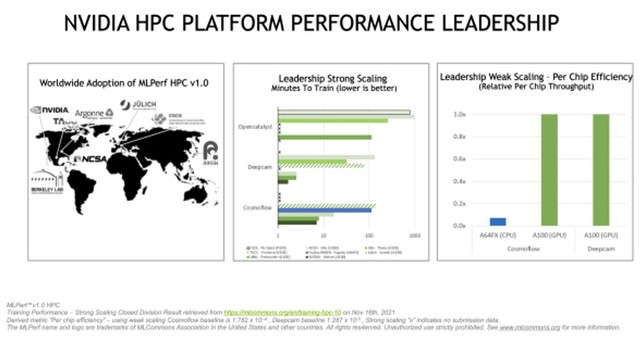
NVIDIA在模型训练速度和每芯片效率方面取得领先
为了推动HPC与AI的协同发展,NVIDIA推出了一系列用于高性能计算的新的库和软件开发工具套件,包括ReOpt(可提高规模高达10万亿美元的物流行业的运营效率)、cuQuantum(可加速量子计算研究)、cuNumeric(为Python社区的科学家、数据科学家、机器学习和人工智能研究人员加速NumPy)。NVIDIA的虚拟世界模拟和3D工作流协作平台Omniverse则负责把一切整合到一起,Omniverse可以用来模拟仓库、工厂、物理和生物系统、5G边缘、机器人、自动驾驶汽车,以及虚拟形象的数字孪生。
推动HPC+AI普惠创新
毫无疑问,NVIDIA拉近了HPC与AI的距离,并让更多的企业和个人受益于此。例如在MLPerf测试中,NVIDIA使用了每个人都会用的工具来调整代码,包括可以加速数据处理的NVIDIA DALI和能够减少小批量延迟的CUDA Graphs,追踪将横向扩展到1024个或更多个 GPU。在戈登贝尔奖的决赛阶段,美国橡树岭国家实验室(ORNL)的研究人员将NLP应用于筛选新药的化学化合物问题,他们使用了一个包含96亿分子的数据集(这是迄今为止应用于此项任务的最大的数据集),在两小时内训练了一个能够加速新药发现的BERT NLP模型。此前的最佳成果是耗费四天时间,用一个包含11亿分子的数据集来训练一个模型。该研究工作在Summit超级计算机上使用了超过2.4万个NVIDIA GPU,提供603 petaflops的性能。该模型现已训练完成,可在单一GPU上运行,帮助研究人员找到可以抑制COVID和其他疾病的化学化合物。
此外,NVIDIA还提供了NVIDIA Arm HPC开发者套件和NVIDIA HPC SDK,NVIDIA Arm HPC开发者套件基于技嘉G242-P32 2U服务器,后者包含一个Arm CPU、两个A100 GPU、两个NVIDIA BlueField-2数据处理器,以及NVIDIA HPC SDK工具套件,对单节点和多节点配置均提供支持。首批套件和SDK已应用于洛斯阿拉莫斯国家实验室(LANL)、莱斯特大学、橡树岭国家实验室(ORNL),以及台湾地区的高速网路与计算中心(NCHC),这些机构已成功部署多节点配置,并向用户开放系统以运行HPC代码。除了HPC SDK,NVIDIA还支持了两个常用的深度学习框架PyTorch和TensorFlow。今年年底,RAPIDS软件库套件和NVIDIA Triton推理服务器将推出基于Arm的版本。显然,Arm生态的壮大会让更多的企业和机构受益于HPC+AI的融合发展。
更多应用NVIDIA系统和网络拓展研究工作的案例正在发生。南方卫理公会大学正在安装一台NVIDIA DGX SuperPOD超级计算机,该大学希望这台超级计算机为拥有超过1.2万名学生和2400名教职员工的庞大社区推动机器学习项目的发展。美国中南部还有两所大学也宣布计划使用NVIDIA技术以推动研究高速发展。德克萨斯农工大学和密西西比州立大学均计划使用NVIDIA的400 Gbit/s InfiniBand网络平台,NVIDIA Quantum-2将作为其最新高性能计算机的主干网。此外,英国的一台超级计算机刚刚升级了InfiniBand网络。德克萨斯农工大学已经为研究者提供了四套加速计算系统,这四套系统包含600多个NVIDIA A100 Tensor Core和上一代GPU,其中两个系统使用了较早版本的NVIDIA InfiniBand技术。
面向未来,NVIDIA在持续为CPU“减负”,并大力推进云原生HPC的进展。面对CPU在传统数据中心承担着越来越多的任务,DPU(数据处理器)作为一个完全集成的片上数据中心平台,NVIDIA BlueField DPU可以卸载和管理数据中心的基础设施任务,释放主机的处理器资源,实现更强的安全性和更高效的超级计算编排工作。与NVIDIA Quantum InfiniBand平台相结合,该架构可提供最佳裸机性能,原生支持多节点租户隔离。而借助NVIDIA Quantum-2,用户可以获得裸机高性能和安全多租户优势,让下一代超级计算机实现安全性、云原生和更高的效率。



本文属于原创文章,如若转载,请注明来源:构建面向未来的数字孪生 NVIDIA助力HPC+AI应对全球挑战https://server.zol.com.cn/781/7815074.html